传统的硬件描述语言(HDL)编写与验证流程正面临严峻挑战,开发周期的压缩与设计质量的提升成为企业生存的核心诉求。近年来,大语言模型(LLM)在软件工程领域的卓越表现,尤其是Cursor和Gemini等工具展示出的语义理解与代码生成能力,为 RTL 设计提供了新的技术路径。然而,芯片设计的核心在于知识产权(IP)的绝对安全,因此,构建一套性能比肩Cursor且能实现物理隔离、本地化部署的RTL辅助设计与验证体系,已成为半导体企业数字化转型的核心课题。
1. RTL大模型内核的选型与性能评估#
构建本地化系统的首要任务是选择合适的基础模型。不同于通用编程模型,RTL设计要求模型对时序并发、时钟域交叉(CDC)、复位逻辑及硬件特有的语法约束有深层理解。
1.1 开源编程模型的竞争格局#
目前的开源模型中,Qwen2.5-Coder、DeepSeek-Coder-V2和Llama 3.1系列处于第一梯队。Qwen2.5-Coder系列在5.5万亿token的多语言语料上进行了预训练,其32B版本在编程能力上被认为已达到GPT-4o的同等水平,支持高达128K的上下文窗口,能够覆盖中型SoC子系统的代码关联需求。DeepSeek-Coder-V2则采用了混合专家(MoE)架构,总参数量虽大,但单次推理激活的参数量(21B)较低,使其在保持高性能的同时显著降低了对计算资源的消耗。
| 模型名称 | 架构类型 | 训练Token量 | 支持语言数 | 上下文长度 | 核心优势 |
|---|---|---|---|---|---|
| Qwen2.5-Coder-32B | Dense | 5.5T | 40+ 主要语言 | 128k | 极强的代码修复与逻辑推理性能 |
| DeepSeek-Coder-V2 | MoE | 10.2T | 338 | 128k | 极高的推理效率与广泛的语言支持 |
| Llama 3.1-70B | Dense | 15T | 通用/代码 | 128k | 生态兼容性最强,推理稳定性高 |
| StarCoder2-15B | Dense | 1T | 600+ | 16k | 针对库文件与Git提交信息有深度优化 |
1.2 硬件专用微调模型的崛起#
通用模型虽然在语法上表现尚可,但在遵循硬件设计规范(如同步复位优先、避免锁存器推断)方面往往不及经过领域微调的模型。RTLCoder、CodeV和VeriCoder等模型通过在过滤后的高质量Verilog数据集(如VerilogDB)上进行监督微调(SFT),显著提升了功能正确性。 以CodeV为例,该模型采用了“多级总结”策略,利用GPT-3.5对真实世界的RTL代码进行逆向描述生成,从而构建了高质量的“指令-代码”对。实验表明,CodeV在RTLLM基准测试中的表现优于GPT-4,展示了专用微调在解决硬件设计“幻觉”方面的巨大潜力。最新的研究如CodeV-R1,则进一步结合了DeepSeek-R1的推理链能力,通过强化学习(RL)引导模型在生成代码前进行逻辑思考,使其在复杂的协议实现任务中取得了突破。
1.3 基准测试与性能比对#
评估本地模型在RTL任务中的实际效能,主要参考VerilogEval(侧重补全)和RTLLM(侧重合成与验证)。
| 模型/方法 | VerilogEval-Machine (Pass@1) | RTLLM v1.1 (Pass@1) | 资源需求 (4-bit) |
|---|---|---|---|
| GPT-4o (云端基准) | 67.7% | 33.8% | N/A |
| CodeV-R1-7B (本地) | 68.6% | 72.9% | ~6GB VRAM |
| Qwen2.5-Coder-32B | 66.6% | 47.9% | ~20GB VRAM |
| RTL-Coder-6.7B | 61.2% | 36.8% | ~6GB VRAM |
| StarCoder2-15B | 37.8% | 15.5% | ~12GB VRAM |
数据表明,经过针对性RL训练的小参数模型(如7B量级)在特定硬件指标上已能超越通用巨量模型。这一发现为企业在有限资源下部署高性能AI助理提供了坚实的理论依据。
2. 企业级推理引擎后端建设#
本地部署Cursor类体验的关键不仅在于模型,更在于能够支撑多用户并发请求、低延迟响应的推理后端。
2.1 主流推理后端的技术路线比对#
企业在构建私有服务时,通常在vLLM、TensorRT-LLM和Ollama之间进行选择。
- vLLM:是目前高吞吐量生产环境的事实标准。其核心贡献是PagedAttention(分页注意力)技术,该技术模仿操作系统的虚拟内存管理,将KV缓存(Key-Value Cache)切分为固定大小的页面,从而彻底解决了内存碎片化问题。在并发用户数超过10人时,vLLM的吞吐量可达Ollama的10倍以上。
- TensorRT-LLM:作为NVIDIA官方推出的深度优化框架,其通过内核融合(Kernel Fusion)和FP8精度的原生支持,在NVIDIA硬件上能够榨取极致的推理速度。对于延迟极其敏感的实时代码补全任务,TensorRT-LLM相较于通用框架有20%-40%的性能领先。
- Ollama:虽然其并发调度能力较弱,但其“Docker化”的部署体验极大地降低了原型开发难度。对于仅在个人工作站进行尝试的小型团队,Ollama通过集成llama.cpp,在单卡或CPU环境下展现了良好的兼容性。
2.2 显存需求与硬件拓扑设计#
RTL任务的模型规模通常分布在7B到32B之间。为了在本地支撑Cursor的流畅感,推理显存的计算必须考虑模型权重、KV缓存和批处理余量。
| 模型规模 | 浮点精度 (FP16) 显存 | 量化精度 (INT4) 显存 |
|---|---|---|
| 7B / 8B | ~14GB | ~4-6GB |
| 14B / 20B | ~40GB | ~12-16GB |
| 32B / 35B | ~64GB | ~20-24GB |
| 70B+ | ~140GB | ~40-48GB |
对于需要服务多个并发会话的中央服务器,推荐采用多卡张量并行(Tensor Parallelism)架构。研究显示,使用H100 GPU配合vLLM或TensorRT-LLM,在FP8量化下可实现每秒数千个token的产出速率,确保在大型项目搜索或代码重构时,工程师无需长时间等待。
3. IDE层级的本地化集成方案#
Cursor的成功在于其对编辑器上下文的深度集成。要实现这一体验,企业可以采用插件+私有后端的松耦合架构。
3.1 Continue.dev:万能本地连接器#
Continue是一个开源的IDE插件(支持VS Code和JetBrains),被广泛视为 Cursor 的最佳本地化替代品。其允许开发者自定义模型路由,将不同的任务分发给不同的本地模型。
- 多模型协同架构:可以在
config.json中配置:将轻量级模型(如Qwen2.5-Coder 1.5B/7B)分配给“tabAutocomplete”通道,以实现毫秒级的代码补全体验;而将推理能力更强的大模型(如Qwen2.5-Coder 32B或DeepSeek-R1 32B)分配给“chat”通道,处理复杂的逻辑问答和代码重构。 - 上下文增强:Continue支持通过
@codebase或@docs指令引入项目上下文。在本地环境下,插件会自动通过嵌入模型(Embedding Model)为当前工作区建立索引,从而实现跨文件的语义跳转和IP复用分析。
3.2 Tabby与代码补全#
Tabby是一个专为自托管设计的AI编程助手服务器。它集成了模型推理和向量数据库,能够对企业的整个代码仓进行全量索引。
- Repository-Level RAG:不同于常规的文本切片,Tabby能理解Git仓库的层级结构。当工程师开始编写一个新的模块时,Tabby能检索出内部库中现有的例化(Instantiation)模板和时序逻辑参考,有效减少了重复劳动。
- 团队管控优势:作为中心化的服务端,Tabby便于合规团队进行单一入口审计,确保没有非授权的外部调用,同时可以根据不同部门的权限分发不同的代码索引库。
4. 针对硬件设计的检索增强生成(RAG)深度优化#
通用的RAG技术在处理RTL代码和硬件规格书(Spec)时常因无法理解层级关系而失效。构建一套“EDA语义感知”的检索系统是本地部署成功的关键。
4.1 结构化硬件文档的解析策略#
硬件文档包含大量表格(如寄存器表、引脚定义)和图表。传统的固定长度切片(Chunking)会撕裂语义。
- 层级感知解析:建议引入LlamaParse或Unstructured等工具,专门针对PDF中的章节层级(Section 3.1.2)进行树状存储。解析 Liberty(.lib)文件时,应将其转化为结构化的JSON,提取出每个标准单元(Standard Cell)的关键时序与功耗参数(如propagation delay, setup/hold time),以便LLM在进行PPA优化建议时能精准调用数据。
- SDC约束的处理:时序约束文件(SDC)具有极强的逻辑关联性。应采用基于正则表达式与语义标签结合的方法,将
create_clock与相关的set_false_path划归为同一知识单元。实验显示,结构化解析能将复杂查询的召回准确度从31%提升至79%。
4.2 知识图谱(KG)增强检索#
硬件设计的本质是信号间的连通与反馈,这与图结构高度吻合。
- VeriGRAG架构:该方案通过提取Verilog代码中的数据路径图(DPG),利用图神经网络(GNN)生成结构化嵌入。当工程师询问“信号A如何影响输出端B”时,系统不再仅仅寻找包含这两个名字的代码片段,而是通过图遍历(Traversal)找回真实的逻辑传播路径,极大地降低了LLM在解释复杂逻辑时的幻觉率。
- 混合检索机制:生产环境下可采用“向量搜索 + BM25关键字匹配”的混合模式。向量搜索负责捕捉语义意图(如“握手协议实现”),而BM25则确保诸如
inst_reg_0_addr等具体的工程命名能够被精确命中。
5. 设计与验证的闭环自动化(Agentic Workflow)#
Cursor的“效果好”不仅来自补全,还来自其尝试运行和纠错的能力。在本地环境中,这需要将LLM与既有的EDA工具链深度联动。
5.1 基于编译器反馈的自修复流#
LLM生成的Verilog代码常含有微小的语法错误或非合成逻辑。
- Verilator/VCS反馈环:建立一个多代理(Multi-agent)工作流。第一个Agent根据需求生成初始RTL代码;第二个Agent负责调用本地的Verilator进行静态语法检查;第三个Agent将编译器的错误日志(Log)重新喂回LLM进行修复。
- Log2BetterRTL技术:研究表明,这种基于日志的闭环反馈能将语法正确率提升约18%,并显著减少Lint违规项(如阻塞/非阻塞赋值混用)。这种迭代修复的过程能在分钟级完成,替代了原本数小时的人工纠错。
5.2 验证套件的高效合成#
验证工作量通常占整个芯片设计周期的60%-70%。
- SVA断言生成:利用LLM从自然语言规格书中提取时序逻辑,并自动转换为SystemVerilog Assertions。例如,将“请求必须在2个时钟周期内得到确认”转换为
property req_ack_p; @(posedge clk) req |-> ##[1:2] ack; endproperty。这种方式能将手工编写断言的工作量降低70%以上。 - 激励生成与覆盖率闭环:AI Agent可以根据功能描述自动生成UVM测试序列(Sequence),并根据上一次仿真运行的覆盖率报告(Coverage Report),自动生成能够触发冷门分支(Corner Cases)的随机测试向量。
5.3 synopsys eda 能力#
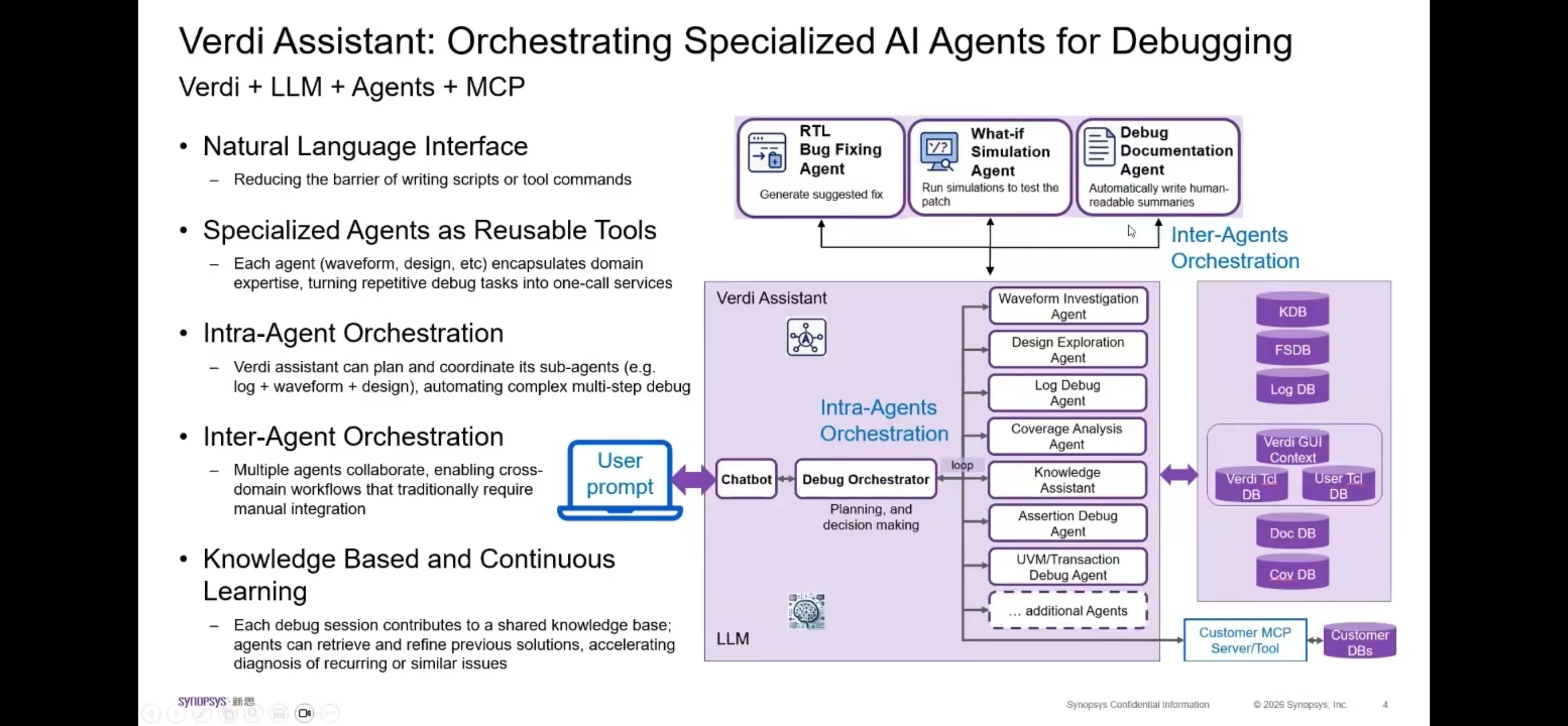
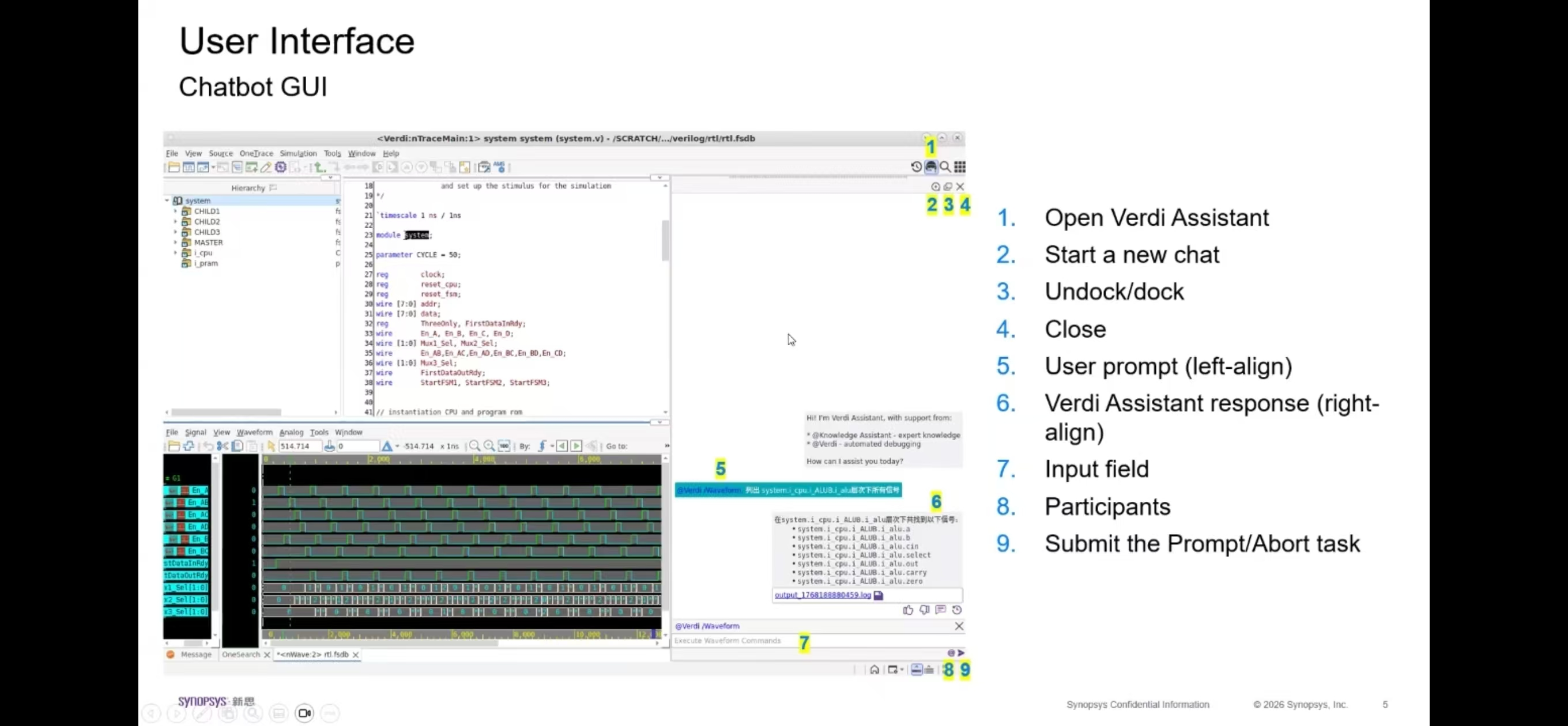
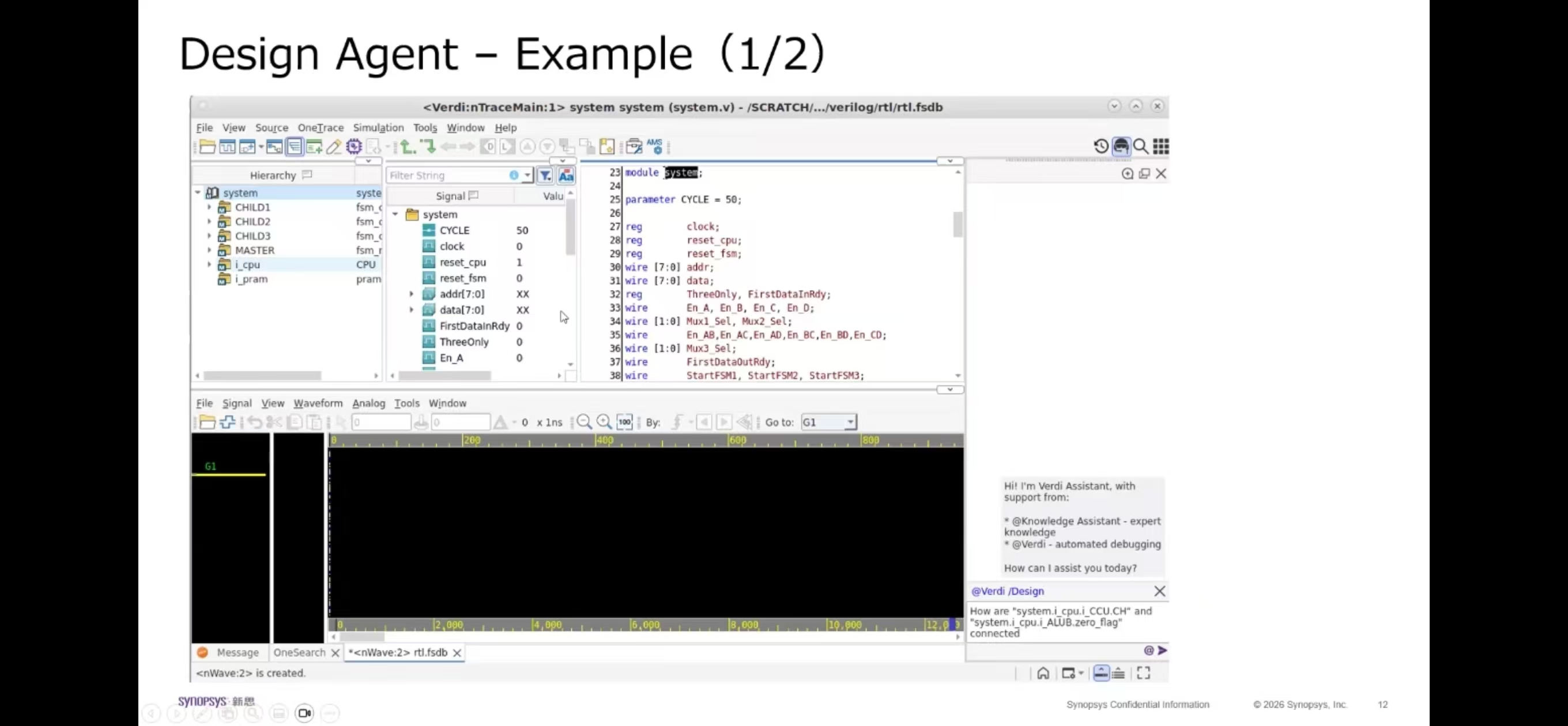
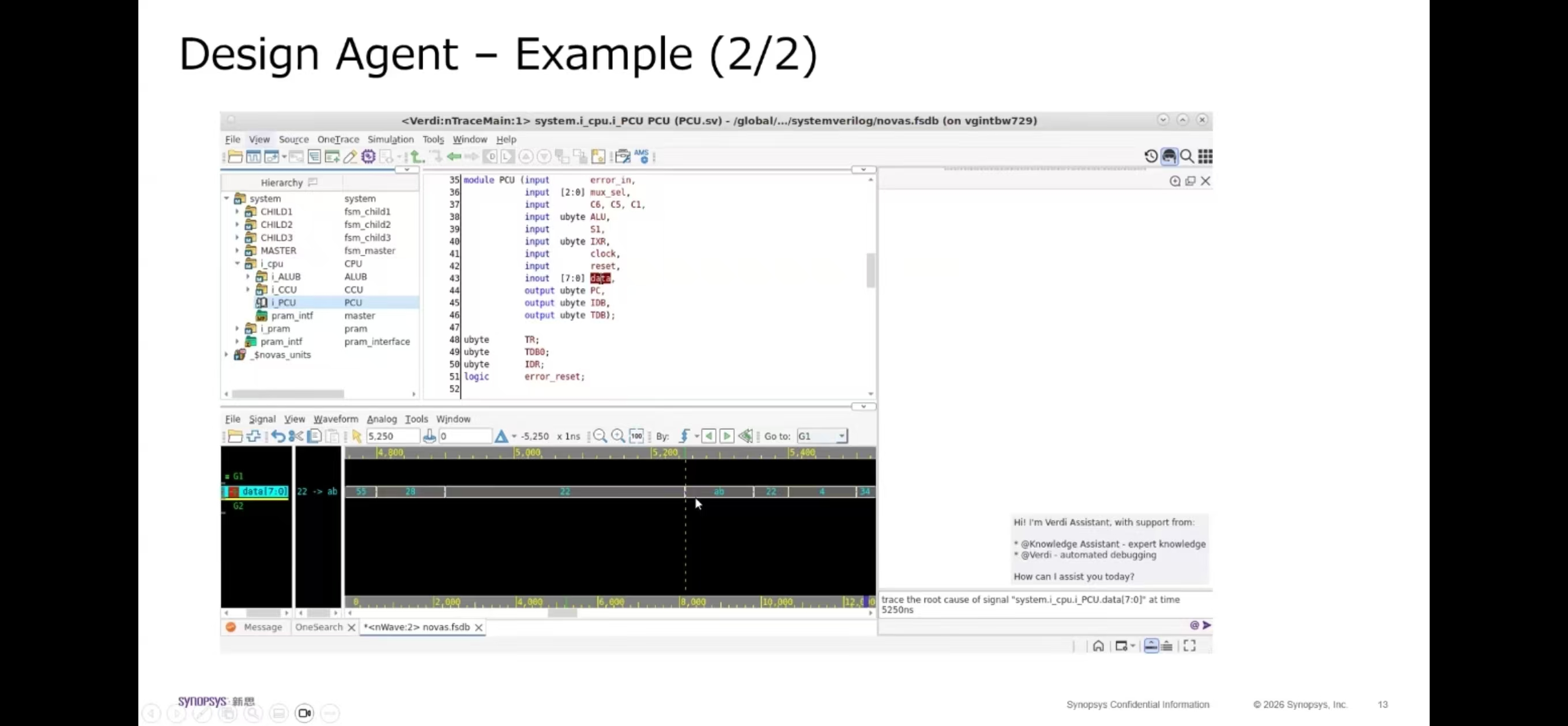
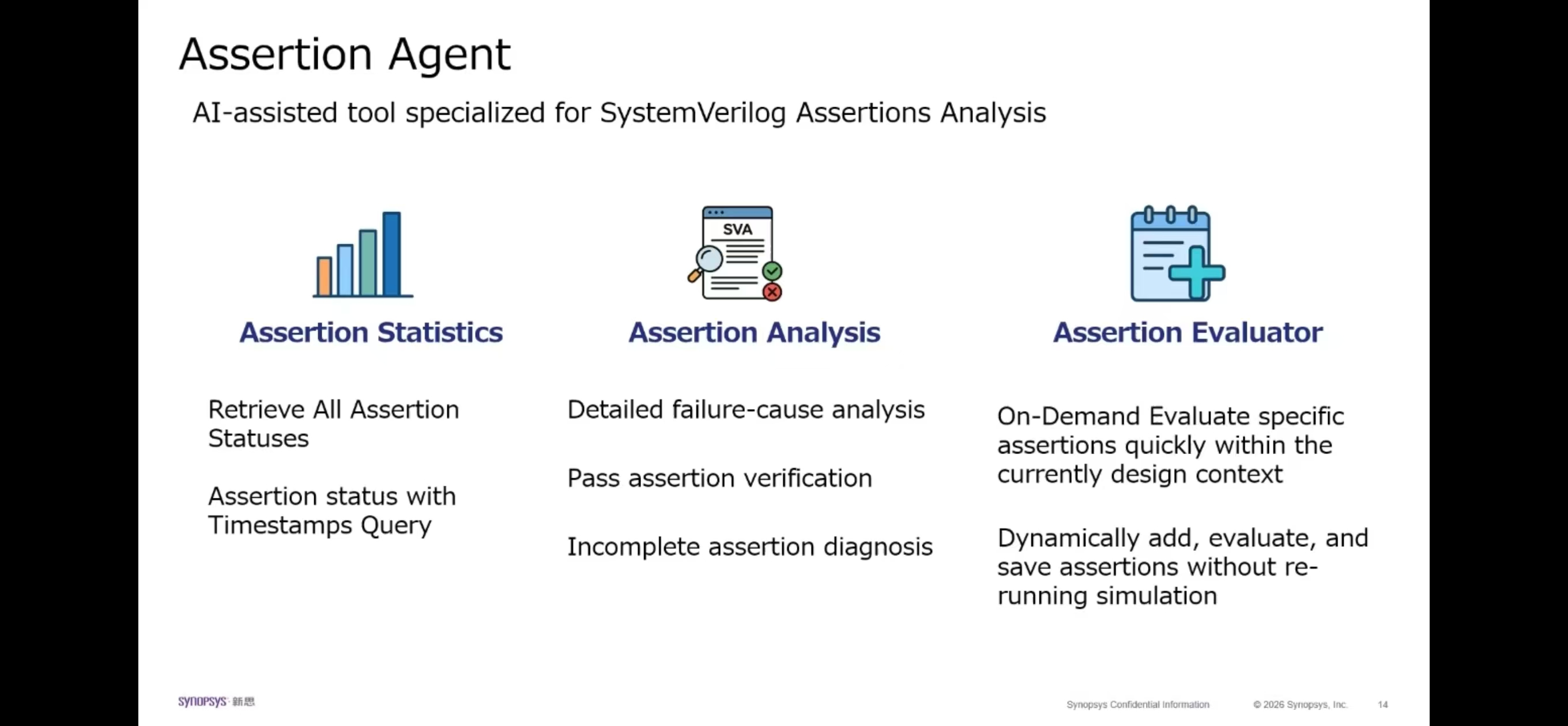
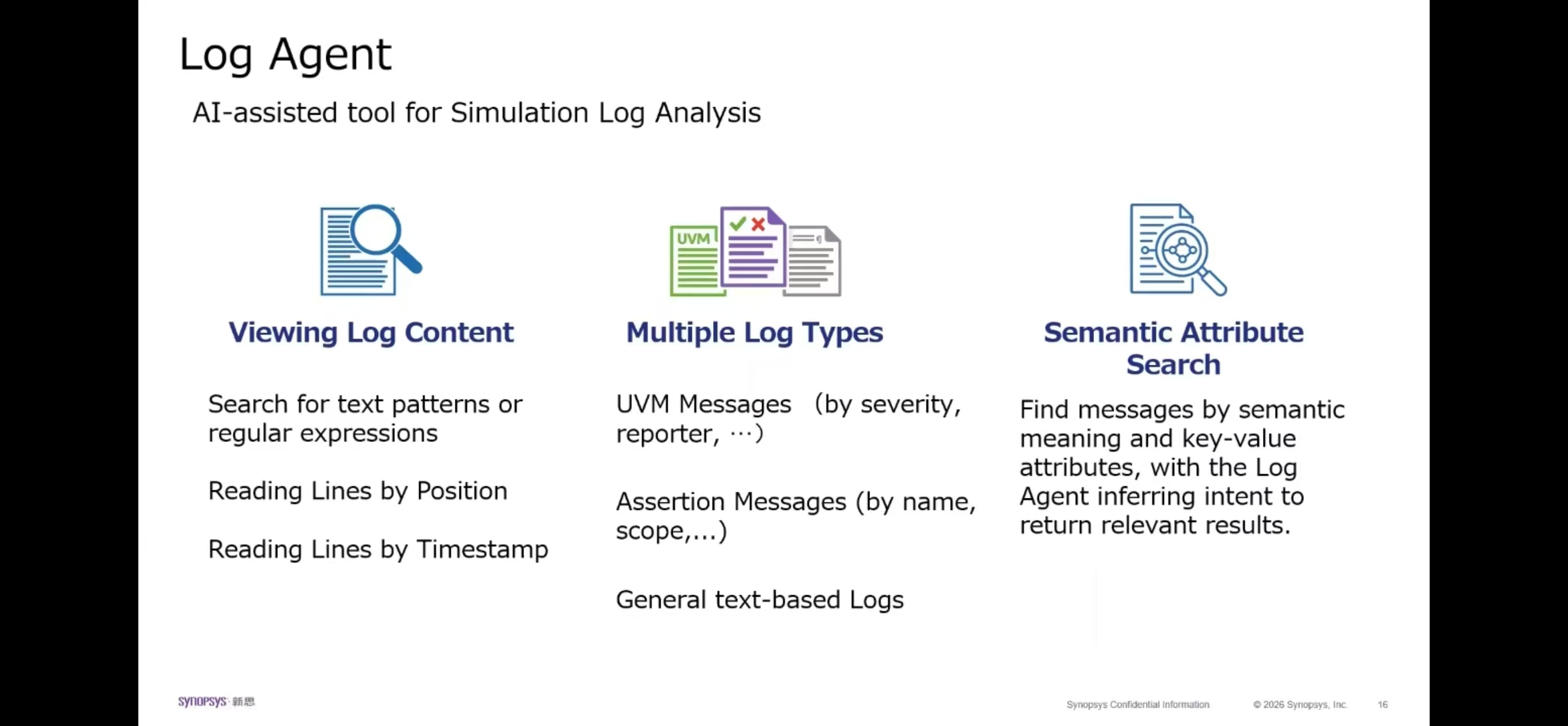
6. 算力架构计算与显存模型建议#
在多卡并行环境中,通信带宽往往比单核算力更关键。
6.1 并行计算策略#
当模型参数超过单卡限制时(如部署70B规模的底座模型),必须采用并行技术。
- 张量并行(TP):将模型的各层横向切割并分布在多个显卡上。这种方式最适合单节点内的多显卡环境,因为它对GPU间的互联带宽要求极高。建议利用NVLink提供的600GB/s或900GB/s双向带宽。
- 流水线并行(PP):将模型的不同层纵向分布在不同节点。其带宽要求较低,但会产生计算空泡。在跨服务器集群部署时,这是扩展显存总容量的主要方式。
6.2 显存资源计算公式#
为了确保模型在高负载下不发生OOM(内存溢出),需要精准计算显存消耗: 其中:
- P:模型参数量(如32B)。
- Q_{bytes}:每参数字节数(4-bit量化约为0.5字节)。
- 1.2:框架与激活层冗余系数。
- Batch:并发用户数。
- Context:上下文窗口(如128k)。
- G:GPU卡数。 部分实际测试显示,利用4张A6000(每张显存48G)组成的192G显存池,可以非常从容地运行DeepSeek-Coder-V2(236B量级)的4-bit量化版,并同时支撑20名左右的工程师进行设计任务。 综上所述,通过“强大的开源底座(Qwen/DeepSeek)+ 高并发推理引擎(vLLM)+ 深度IDE集成(Continue)+ 硬件感知RAG”的组合架构,企业完全可以在不牺牲安全性的前提下,获得比肩云端工具的生产力增益。这不仅是开发方式的升级,更是半导体企业在AI时代保护核心竞争力、加速芯片迭代周期的必然选择。